In our first blog post, Adventures in Fabric Vol. One: The Future of Analytics, we explored why Microsoft Fabric is transforming the data analytics landscape. We highlighted its seamless connectivity, flexible storage options, diverse toolset, and Microsoft’s commitment to continuous innovation. We also introduced Fabric Manager, SDK’s accelerator for Microsoft Fabric, designed to simplify implementation and improve project delivery.
In this installment, Adventures in Microsoft Fabric Vol. Two, we dive deeper into Fabric’s storage capabilities—examining the different options, their unique benefits, and best practices for optimizing your data strategy.
Lakehouse, Warehouse, Eventhouse: Understanding Storage in Fabric
One of Microsoft Fabric’s key advantages is its ability to read data in your preferred programming language, regardless of the storage format. Unlike other platforms, Fabric doesn’t require a dedicated compute engine or pool—simply connect to the storage and start querying.
All data in Fabric is stored in the Delta format, an open-source standard that has become the industry benchmark for scalable, high-performance storage. Designed with accessibility in mind, Fabric supports multiple languages, allows for connections to OneLake, and provides compatibility with Unity and Iceberg formats via shortcuts or mirroring.
Choosing the Right Storage Option
In the past, when databases were the primary storage solution, developers rarely had to think about where data was stored—SQL Server handled that behind the scenes. As data lakes gained popularity, storage shifted to a file-based approach, requiring developers to create structured folder and file naming conventions to keep things organized.
Microsoft Fabric bridges the gap by offering flexible storage options that combine the strengths of traditional databases with the versatility of data lakes. But with multiple choices, how do you know which one is right for your use case?
Here’s a breakdown of Fabric’s core storage types (or houses):
| Storage Type | Primary Purpose | Development Approach |
|---|---|---|
| Lakehouse | Large data, multi-purpose, most flexibility. Files and tables | Notebooks, PySpark, or Spark SQL |
| Warehouse | Geared to structured data | SQL Scripts and Stored Procedures |
| Eventhouse | Real-time, time-series, and geospatial | Eventstream and KQL Queryset |
| Semantic Model | Final layer for business interactivity for reports and ad hoc | Power BI |
| SQL Database | Operational or application database | SQL Scripts and Stored Procedures |
New Feature Alert: Microsoft recently released a Spark connector, enabling seamless writing from notebooks to a Warehouse. Expect continuous evolution in storage capabilities.
Which House Is Right for You?
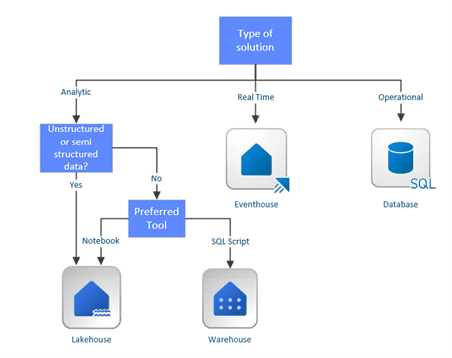
Choosing the right storage depends on four key factors:
- Type of solution
- Type of data
- Preferred tools and team skills
- Required features
Analytics Use Case
Let’s focus on an analytics use case that refreshes hourly or daily. With this use case, two storage layers are necessary, and therefore, two storage decisions must be made:
- Ingestion Layer — Sometimes called bronze and silver layers, this layer is a staging area for all data types and is similar to staging in traditional data warehouses.
- Gold Layer — This is the final, consumption-ready layer optimized for reporting and analytics; it functions like a Data Mart or Data Warehouse.
Ingestion Layer
For our Ingestion Layer, we need the flexibility to store any type of data. Lakehouse is the clear winner because it supports all data formats—structured (tables), semi-structured (JSON), and unstructured (images). If any of the data isn’t in table format, the Lakehouse provides a place to store it as files.
You might be thinking, “But wait! All my sources are databases, so why would I need a Lakehouse?” While that may be true today, more and more sources are semi-structured, and using only a Warehouse may limit your ability to handle those data types in the future. Choosing Lakehouse also future-proofs your solution by giving you a storage layer that can support both schema-based and schema-less data structures.
Gold Layer
For the Gold Layer, there’s more to consider, particularly when it comes to toolsets and preferred languages.
-
Writing Tools Differ Between Storage Types:
While data can be read using any tool, writing is typically done with one: Notebooks for Lakehouse and SQL Scripts for Warehouse.
-
Team Expertise Matters:
If the team is comfortable with SQL and stored procedures, Warehouse may be the better choice. If the team primarily works with Spark, then Lakehouse is the way to go. Notebooks can write in Spark SQL to a Lakehouse. While the syntax is slightly different, it’s highly transferable.
-
Security Considerations:
Both Lakehouse and Warehouse offer object/column/row level security. However, Lakehouse applies an all-or-none security model when accessed through a Notebook. Fine-grained security is only available through the SQL Endpoint.
-
Features and Limitations:
It’s best to check the official documentation for the most up-to-date feature set. For example, at the time of development, Warehouse did not support the merge function, leading us to use Lakehouse. In addition, Warehouse supported dynamic masking. If that had been a requirement, Warehouse would have been the preferred choice.
What About the Other Storage?
Eventhouse is designed for real-time and time-series data, offering a highly performant storage solution for event-based messages. It can function as a standalone, non-analytics solution or serve as an additional storage layer to handle real-time messages while the main analytics solution performs the heavy transformations.
SQL Database in Fabric is a newly released storage option, still in preview, primarily targeted at operational and application use cases. However, we also see potential for it to be used as a DataMart in certain scenarios. Currently, SQL Database has a 4TB limit. We’re particularly interested in how Warehouse and SQL Database storage will evolve in the future and how they might complement each other.
Shortcuts: Eliminating Redundancy
A few years ago, sharing files meant emailing them back and forth, resulting in multiple saved copies, different versions, and confusion over which one was correct. Now, instead of duplicating files, we share a link to a single source—this same principle applies to data shortcuts in Fabric. Shortcuts are links for data.
Fabric was designed with the idea that data should exist in only one copy, in the format you need it. However, in large data lakes, we often see multiple copies of the same data scattered across different projects. For example, on a machine learning project, the data scientists copy the data to their sandbox. A citizen developer wants to add additional data, thus creating another copy.
Having multiple copies of the same data not only increases complexity and storage costs but also raises the risk of inconsistent insights across different teams. Shortcuts solve this problem by enabling direct access to existing data without duplication, ensuring that everyone works for a single, trusted source.
Shortcuts are available across all Fabric storage types and are expanding to support more external storage solutions. Organizations can ingest data once, then seamlessly share it with data builders and consumers. Additionally, shortcuts integrate with key external data stores, such as Azure Data Lake Storage (ADLS), meaning there’s no need to copy data into Fabric—just link to it and start analyzing.
Mirroring: Real-Time Data Synchronization
Another way to retrieve and store data in Fabric is mirroring. Mirroring offers low-latency replication using Change Data Capture (CDC), copying all data and transactions to Delta tables in OneLake. Unlike shortcuts, mirroring enables a full replication of the source database within Fabric. The list of supported source systems continues to expand, making this a valuable option for maintaining an up-to-date dataset. Typically, we treat mirrored data as we would a source system, integrating it into the ETL process for further transformation and analysis.
While mirroring helps bring data into Fabric efficiently, the next step is deciding where to store and process that data. Different storage options serve different purposes, and selecting the right one is essential for scalability, performance, and usability.
Which House for SDK’s Fabric Manager?
Fabric Manager is SDK’s accelerator designed to streamline implementation and enhance project delivery within Microsoft Fabric. It provides a structured framework to manage data ingestion, transformation, and governance while maintaining flexibility for different analytics and reporting needs. Our goal at SDK was to build a solution that could seamlessly integrate with various data source, business use cases, and evolving Fabric capabilities.
To achieve this, we had to make a strategic decision around storage based on three key factors:
- The data used in analytics
- The data driven parameters used to ingest and run the platform
- Logging data movement
The Data Used in Analytics
One of the first and most important decisions we made when building Fabric Manager was where to store the analytics data itself. Since we wanted an accelerator that could support multiple use cases, we chose Lakehouse as the foundation. Why?
- We often work with API data in JSON format, which doesn’t fit well into a traditional data warehouse.
- We’re invested in AI-driven opportunities, and having our data structured for future AI integrations was a priority.
- Lakehouse provides flexibility, supporting both structures and semi-structured data while maintaining high performance.
To organize our data efficiently, we followed a Medallion Architecture, a layered approach that ensures data is structured, clean, and optimized for business use:
- Bronze Layer – Raw, unaltered data stored in files, as close to the source as possible.
- Silver Layer – A deduplicated version of the data, with schemas applied and historical changes tracked.
- Gold Layer – A refined dimensional model, transforming data into a business-friendly format.
- Semantic Model – The final version, optimized for reporting and analysis in Power BI, allowing for easy drag and drop interactions.
The Data Driven Parameters Used to Ingest and Run the Platform
At SDK, we often rely on structured databases to manage the data-driven configurations that control ingestion and platform execution. We felt that a Warehouse was best suited for this task as it is tabular in nature, and we often update the values. At the time of development, SQL Database in Fabric was not yet available, but given its operational focus, it is something we may transition to in the future as the platform evolves.
Logging Data Movement
Monitoring and troubleshooting data pipelines is critical for ensuring smooth operations. We needed a centralized solution to capture real-time pipeline activity and store historical logs for trend analysis. To achieve this, we built a centralized logging system using a central Eventhouse.
- Live data tracking – Provides real-time insights into what’s currently running.
- Historical data analysis – Allows us to detect patterns and troubleshoot failures more effectively.
By consolidating all logs and error messages in one place, we created a reliable and scalable monitoring system that ensures transparency and efficiency in our data workflows.
Lessons Learned for SDK’s Fabric Manager
Our storage choices aligned well with the intended purposed, but adapting to Fabric’s new architecture came with a few unexpected hurdles. Since our team was familiar with other storage solutions, we encountered several challenges and limitations along the way:
-
Writing Limitations Across Storage Types:
A common frustration was realizing that each storage type has a designated writing tool. Developers often expected more flexibility but had to adjust. While it makes sense from a technical standpoint, it took time to adapt.
-
Warehouse Missing Key Features:
There are some things you just end up relying on. In Warehouse, lack of Identity Columns and Merge Statements were something that bothered us a lot.
-
SQL Endpoint Refresh Delay:
When reading from a Lakehouse, data is accessed via the SQL Endpoint, which is sometimes cached and out of sync with the latest updates. This lag was especially frustrating because it was intermittent and unpredictable. While there’s a workaround using sample code to manually trigger a refresh, it feels like something that should happen automatically.
-
Limited Schema Support for Lakehouse:
Schema support in Lakehouse is still in preview, and its limitations—particularly around sharing and restricting access through the SQL Endpoint—were significant enough that we chose not to use it for now.
What’s Next? Features We’re Excited to Explore
SDK’s innovation focus has shifted to Generative AI, and the release of SQL Database in Fabric is particularly exciting. Vector data types are now available directly in SQL, which is exactly the kind of data needed for most AI customizations. Having vector storage built directly into SQL means we can store and process AI-related data without needing to move it to a specialized database. This is such a game-changer!
As Fabric continues to evolve, we’re eager to explore new enhancements. Stay tuned for our next Fabric adventure!
Ursula Pflanz, Principal Architect & Head of Innovation at SDK